05 / Fullstack
eda-bench
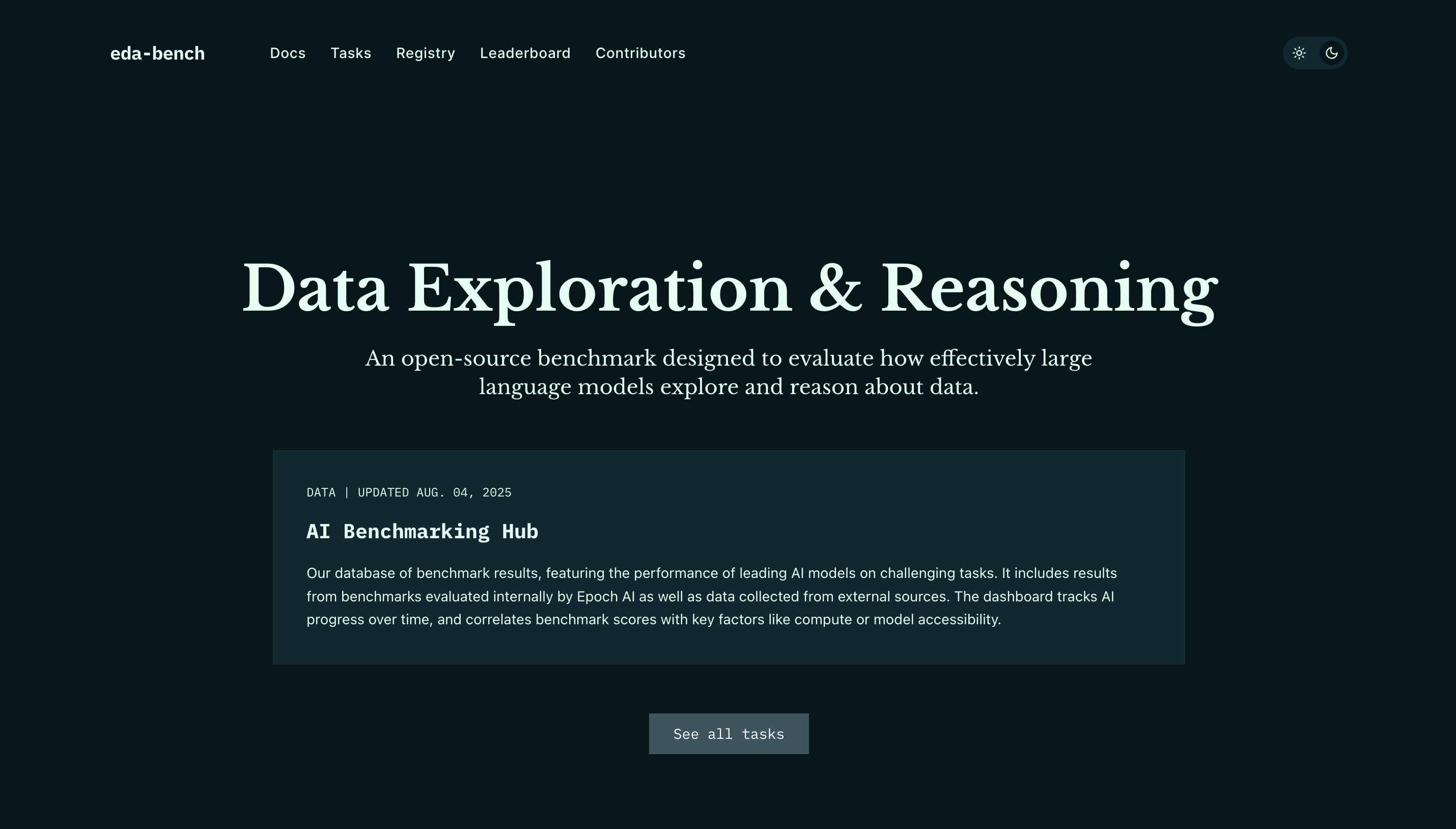
Data Exploration & Reasoning Benchmark
01 / Overview
eda-bench is a research-grade benchmarking site for evaluating how effectively large language models explore and reason about data, with a live leaderboard, task registry, and documentation in one cohesive interface.
02 / The Challenge
Problem
The project needed a public home that could present complex benchmark results in a way that researchers and practitioners could actually use. That meant clear visualizations, a browsable task registry, and proper citation tooling — all without overwhelming visitors or sacrificing speed.
03 / The Approach
Solution
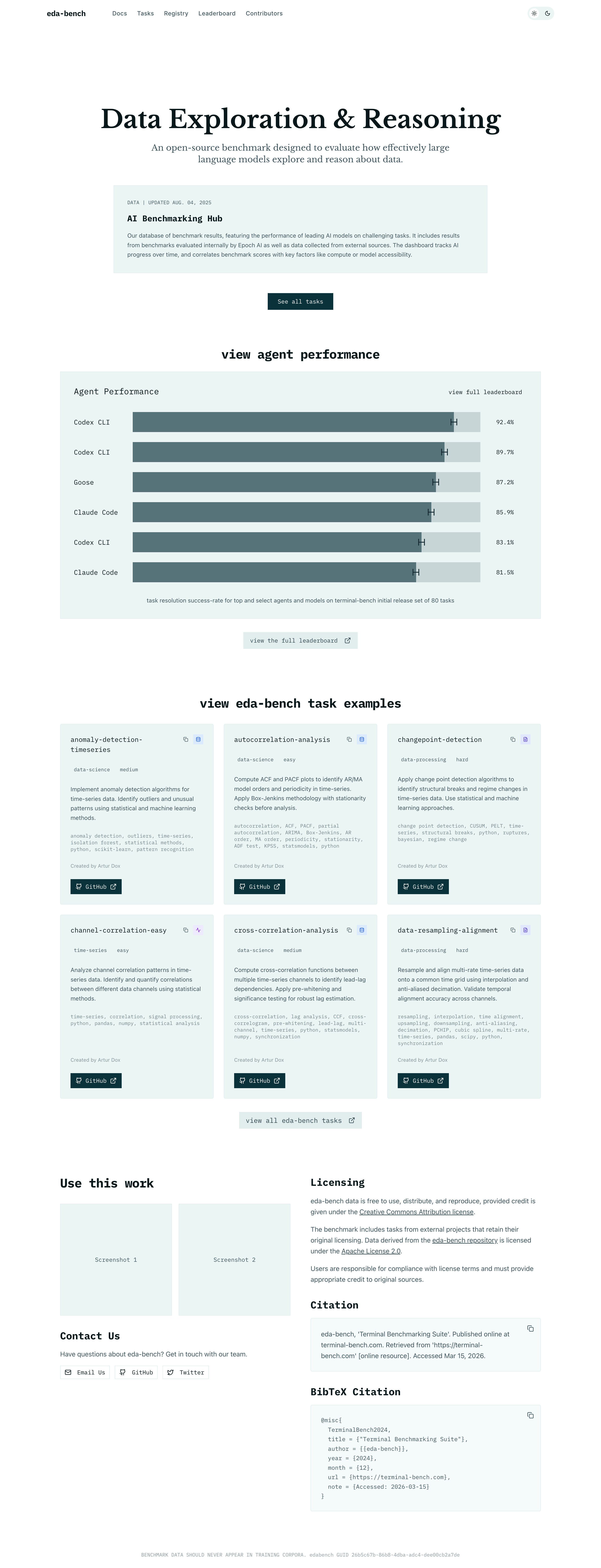
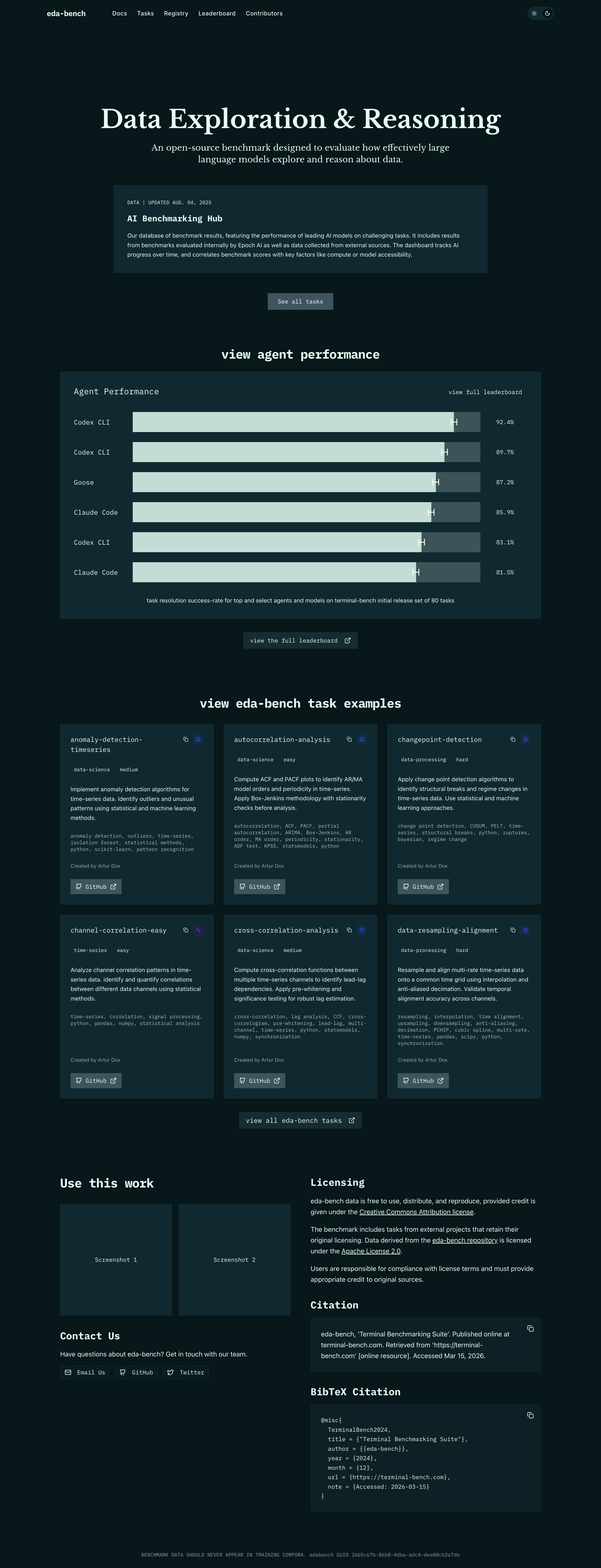
I built a Next.js 16 App Router site with an animated leaderboard, GitHub-backed task registry, and MDX-powered docs. Recharts and GSAP handle agent performance visualizations, while a shared design system built on shadcn/ui ensures the homepage, tasks, registry, docs, and contributors pages all feel like one product.
04 / Features
What I Built
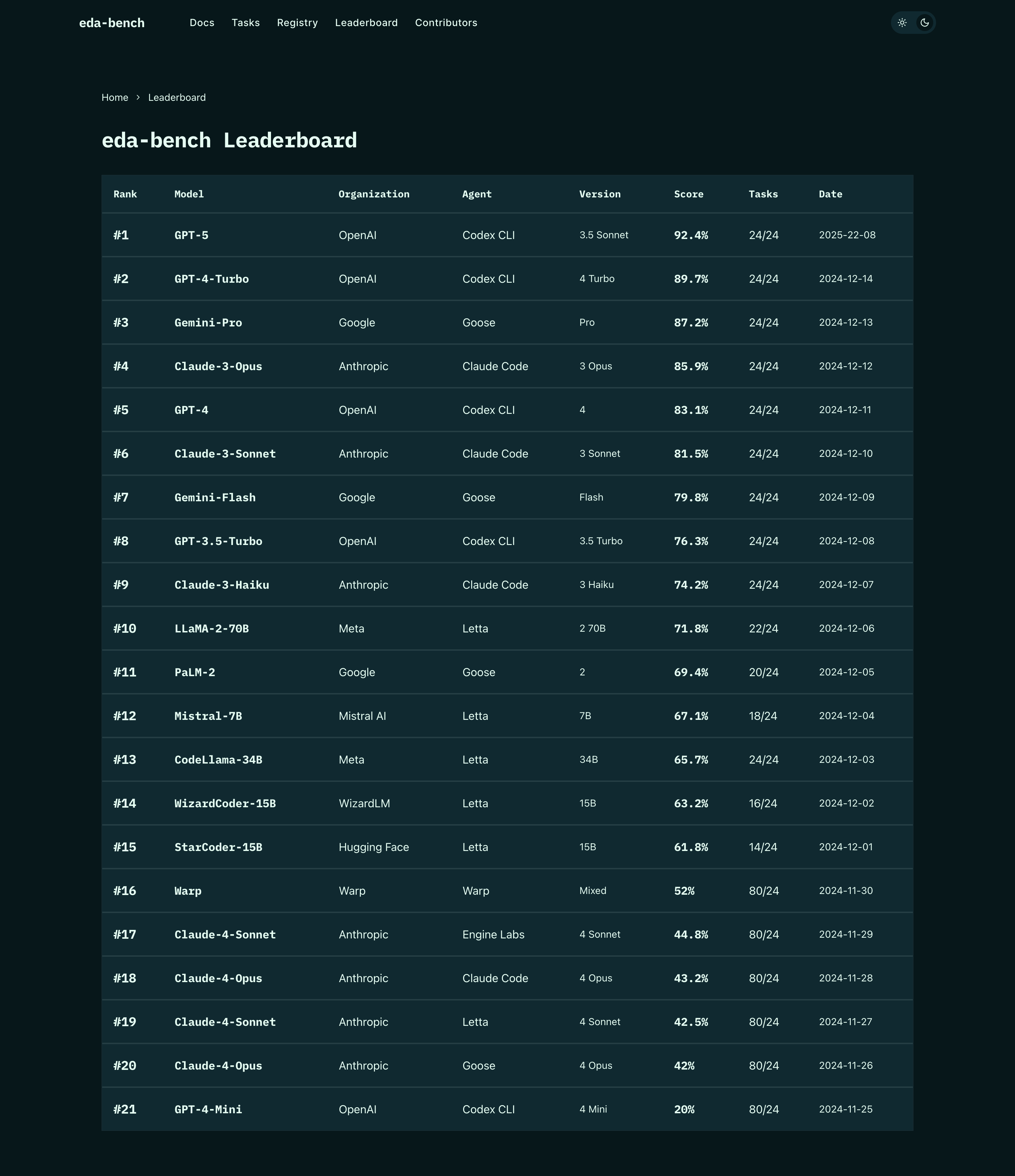
Live Leaderboard
Animated agent performance leaderboard that highlights model, organization, score, and task coverage with smooth GSAP-powered transitions.
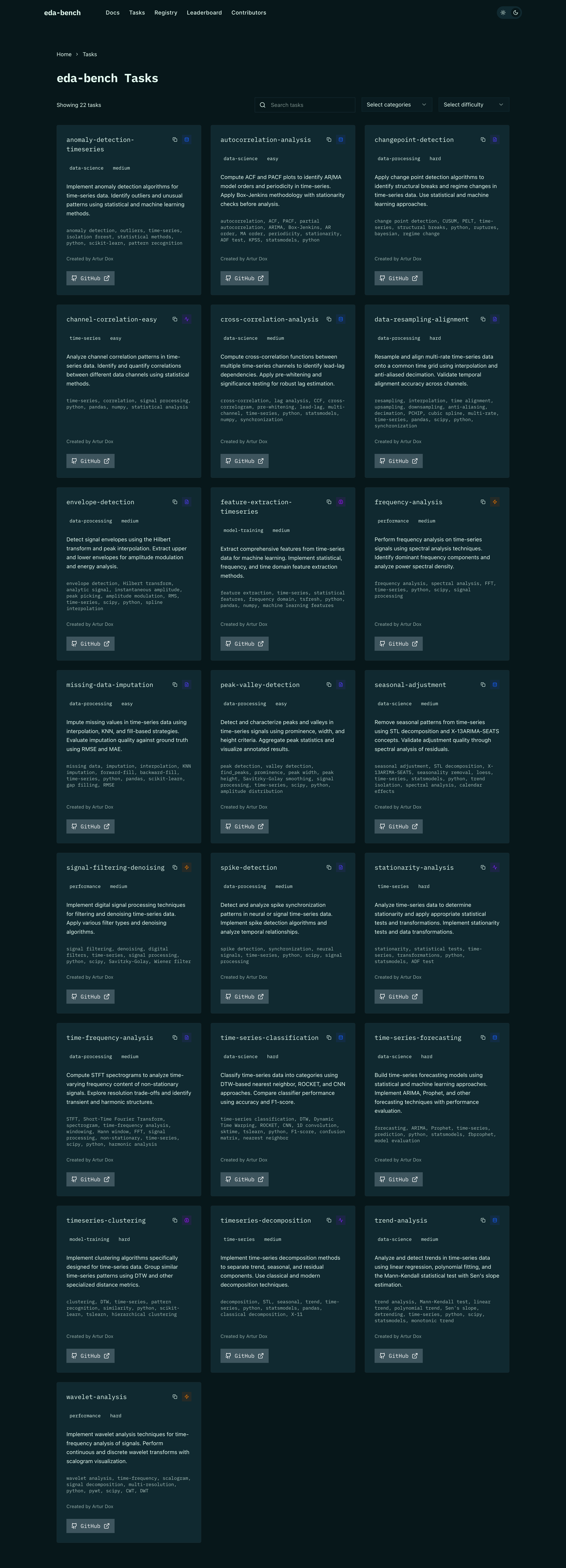
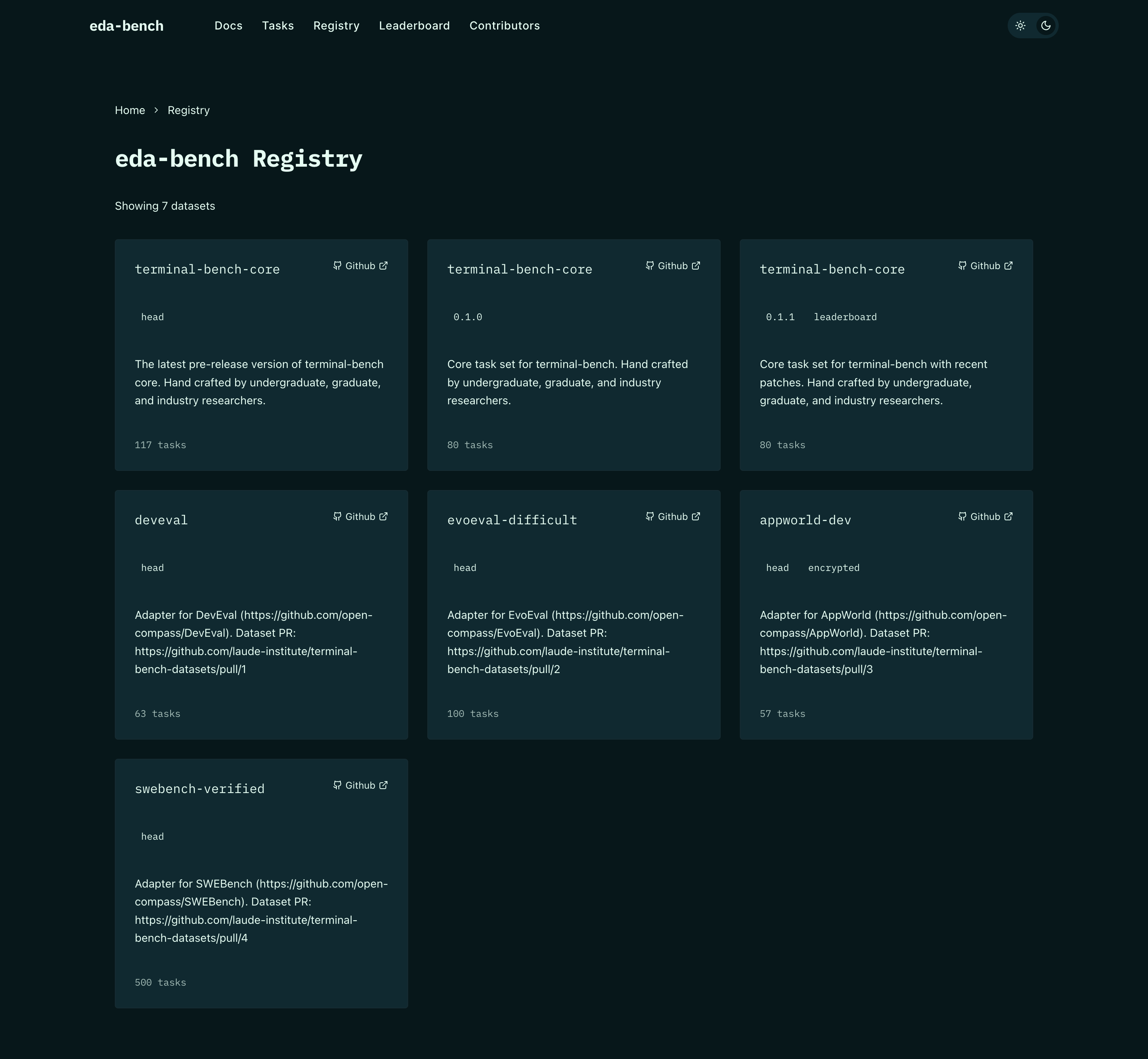
Task Registry
Filterable task browser sourced from GitHub, organized by domain so researchers can quickly see what each benchmark covers.
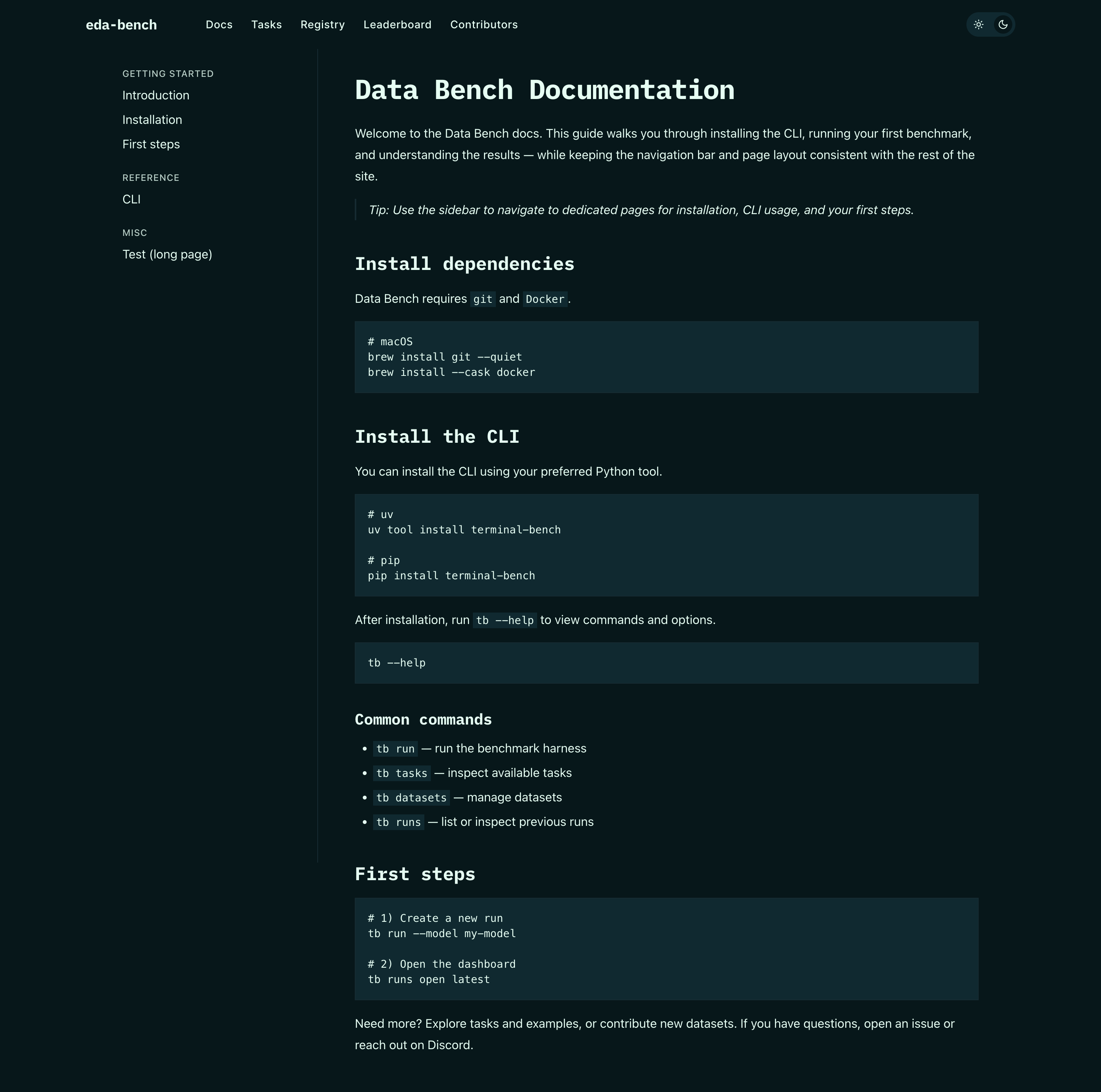
Integrated Docs
MDX documentation for installation, CLI usage, and first steps, sharing navigation and styling with the rest of the site.
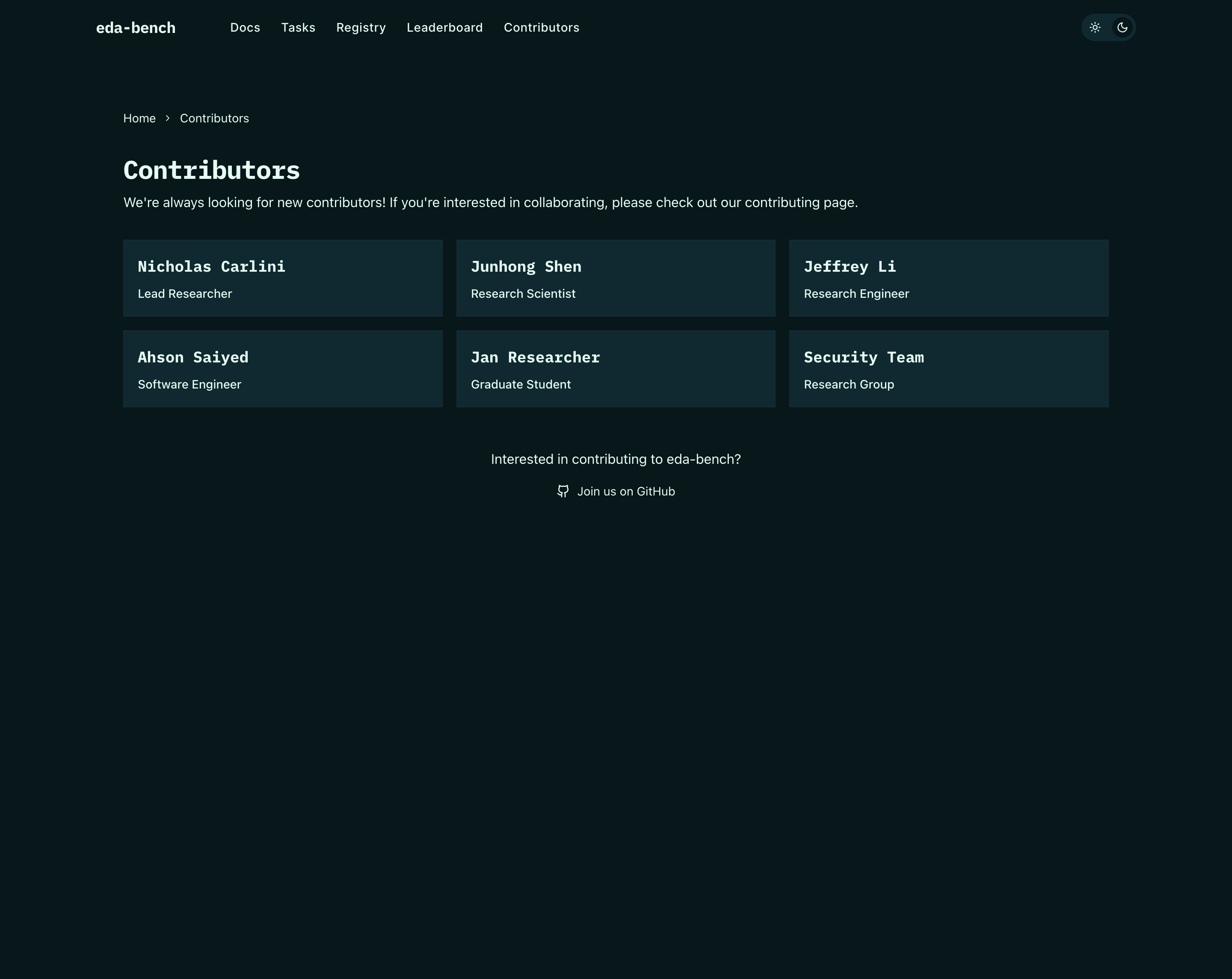
Citation & Presentation
One-click copy for plain text and BibTeX citations plus a contributors page that makes the project easy to reference and extend.
05 / Screens
Product Shots
06 / Outcomes
Results
Single surface
Leaderboard, tasks, docs, and contributors all live under one consistent design system.
Research-ready
Built to support papers, talks, and community contributions rather than just a marketing page.